This question came up on cross validated. In the course of responding to my answer, OP asks “why can’t I adjust for exposure length in a logistic regression” which kind of got me scratching my head. Seems like it could be done.
I brought the question to twitter, and Dr. Ellie Murray responded reminding me that time to death and death are different outcomes and should be treated differently. A logistic regression could be done, depending on what you’re trying to model.
Finally, Frank Harrell responded to Dr. Murray, with a link to a paper by Brad Efron (because of course Efron wrote something on this) which showed how this can be done quite elegantly.
Let’s see how we can use logistic regression for survival analysis.
The Gist
Recall that the Kaplan-Meir product limit estimator looks like
Here, \(d_i\) is the number of subjects who experience the outcome at time \(t_i\), and \(n_i\) is the number of individuals known to have survived up to time \(t_i\). In essence, the product limit estimator is a product of a sequence of probabilities. What else do we use to model probabilities? Logistic regression.
Efron writes that the main assumption for using logistic regression to model these probabilities is that the number of events \(d_i\) is binomial given \(n_i\)
Here, \(h_i\) is the discrete hazard rate (i.e. the probability the subject experiences the outcome during the \(i^{th}\) interval given the subject has survived until the beginning of the \(i^{th}\) interval).
The main problem is that the hazard may not be linear in the exposure time. Efron uses splines to allow \(h_i\) to be flexible in exposure time, and then computes the estimated survival function using
Structure your data so that you have number at risk, number of events, and number of censoring events as columns
Fit a logistic regression on the event/at risk columns (in R this is done by making cbind(y, n-y) the outcome in the glm call). Ensure the time variable is modeled flexibly (either with splines or something more exotic).
Predict the risk of death (i.e. the discrete hazard) from the logistic regression on the observed event times.
Take the cumulative product of one minus the discrete hazards. These are the survival function estimates.
Replicating Efron’s Example
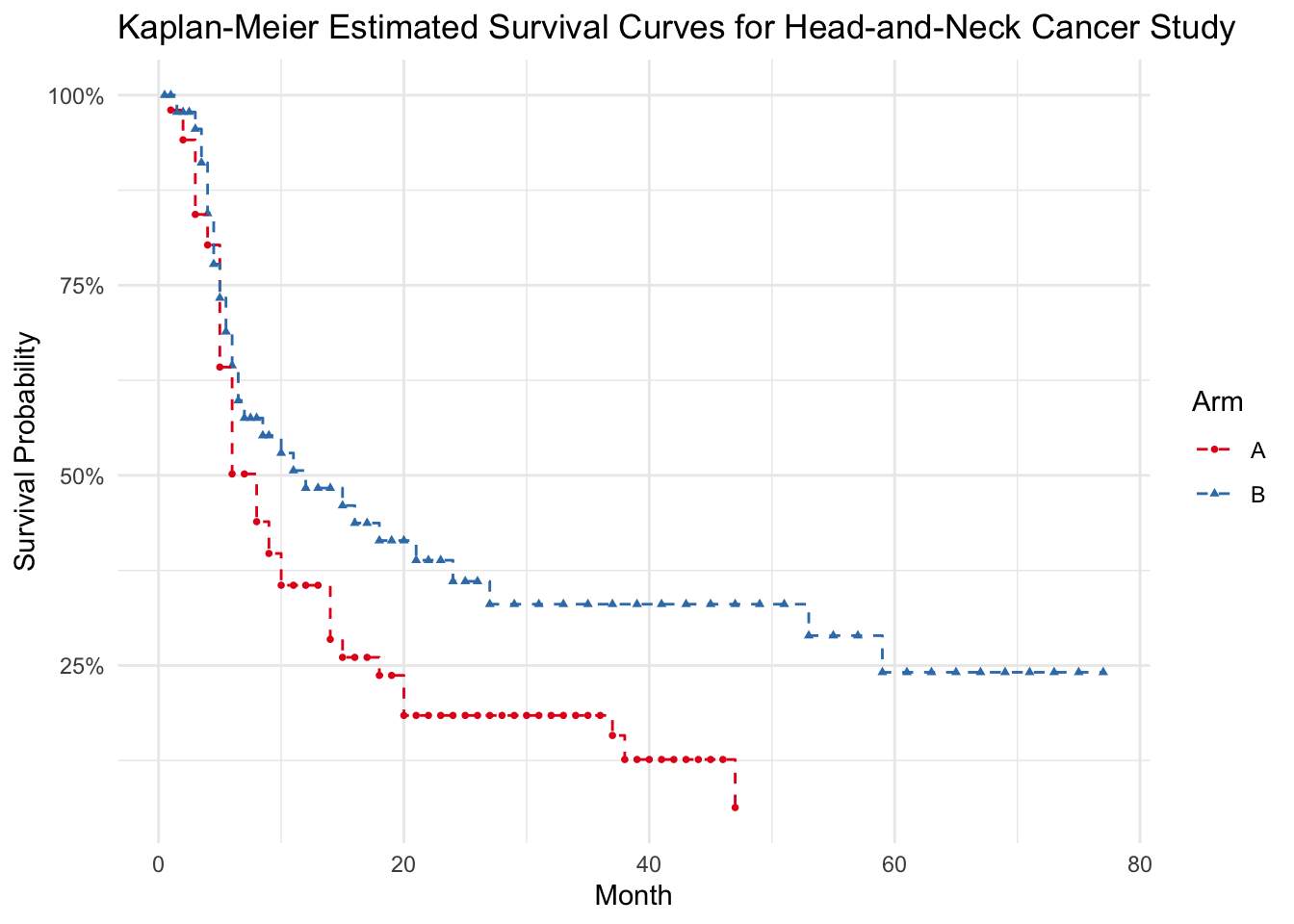
Efron motivates this approach using survival data from a Head-and-Neck cancer study conducted by the Northern California Oncology Group. I’ve extracted this data to replicate the method.
Here, \(t_i\) is the the midpoint between months. This is equivalent to estimating the risk of the outcome between the start of month \(i\) and the start of month \(i+1\). The function \(( z )_- = \min(z, 0)\). This particular expansion allows \(t_i\) to vary as a cubic function before \(t_i=11\), and then as a linear function thereafter.
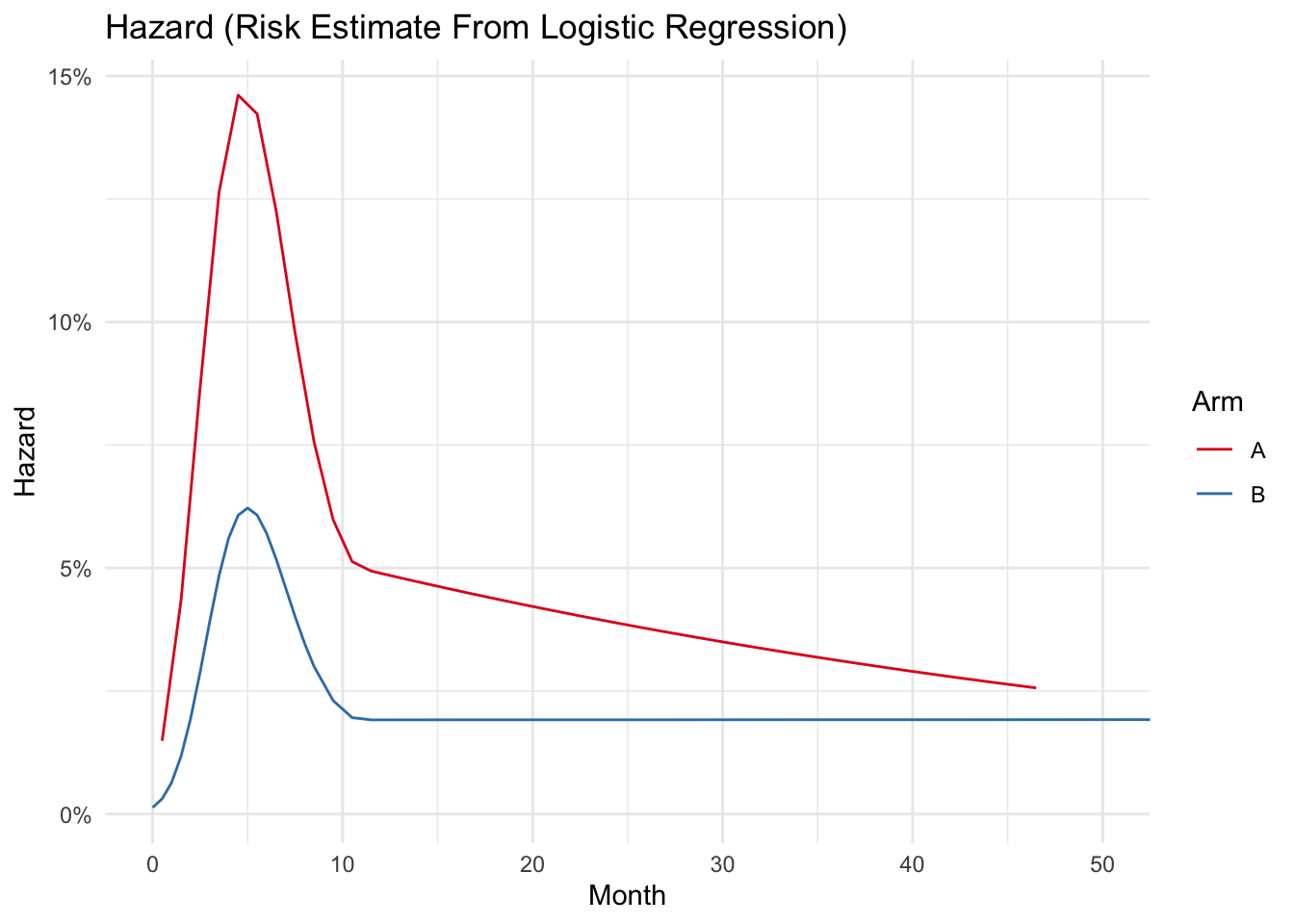
After fitting the model with an interaction by arm (so that the hazards can differ by arm), we can plot the hazards readily 1.
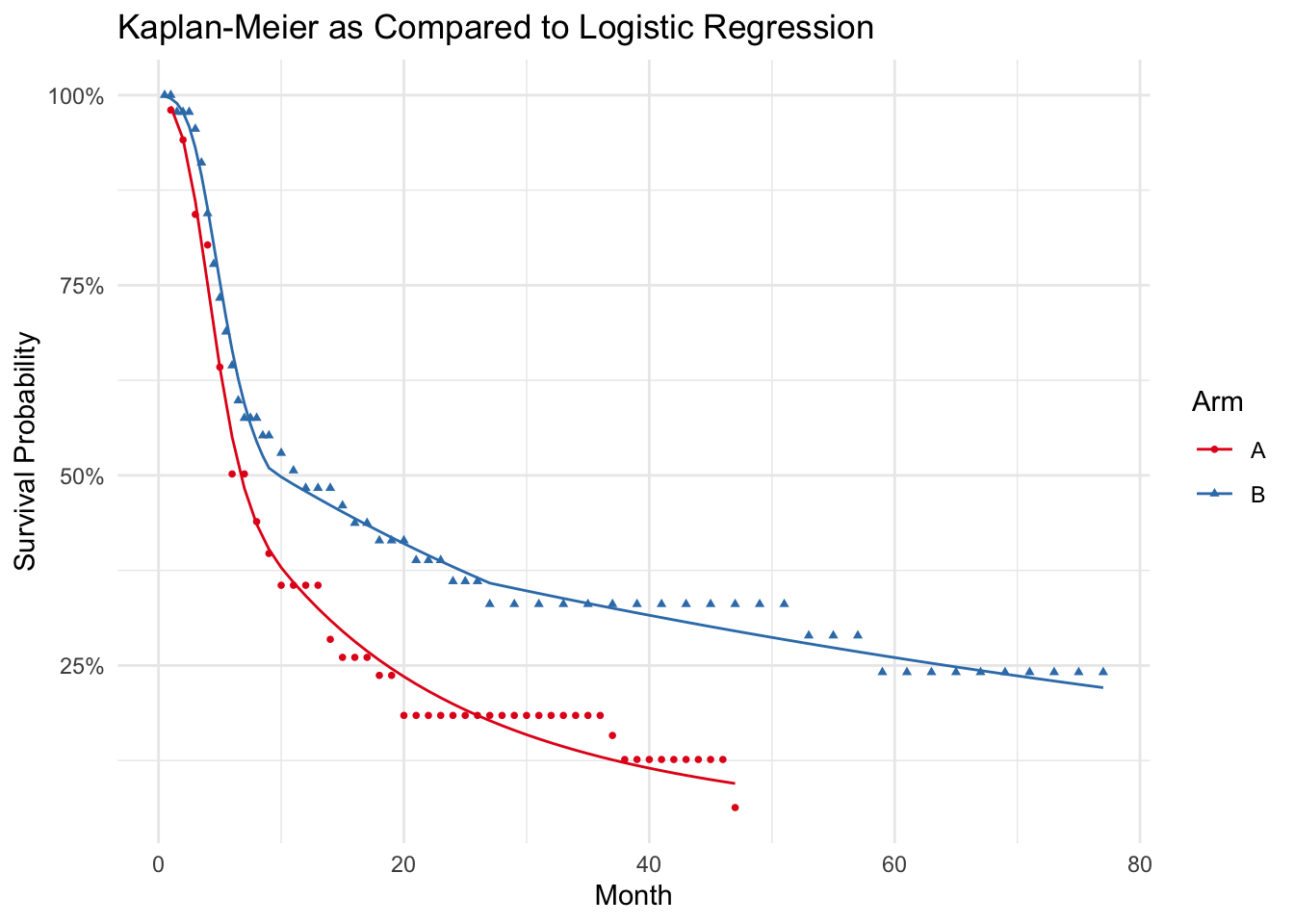
And we can also plot the estimated survival function against the Kaplan Meier to compare.
Code
base_plot +geom_line(data=preds, aes(month, S, color=arm), inherit.aes = F) +labs(title='Kaplan-Meier as Compared to Logistic Regression')
Final Thoughts
Why would we want to parametrically model the hazard when Kaplan-Meir can’t misspecify the hazard? What do we gain from this? In a word: efficiency , at least according to Efron. Additionally, if we are willing to make assumptions about how the hazard evolves into the future (e.g. linearly) then we can use this approach to forecast survival beyond the last observed timepoint.
In his paper, Efron has some notes on computing standard errors for this estimator. Its fairly dense, and I haven’t included confidence intervals here lest I naively compute them. That’s a topic for a future blog post.
Footnotes
I Just can’t get the hazard’s to look the same as Figure 2. Might be an error copying over the data.↩︎