Peeking (looking for significance in an AB test before the experiment has enough samples to reach desired power) is a “no no”. Rationales for not peeking typically mention inflated type 1 error rate.
Unless you’re just randomizing into two groups and not changing anything, the null is unlikely to be true. So inflated type one error rate is really not the primary concern. Rather, if we peek then we are setting ourselves up for disappointment. Detected effects from peeking will typically not generalize, and we will be overstating out impact. The reason why is fairly clear when considering the Winner’s Curse.
The long and the short of it is as follows:
When you peak, your tests are under powered.
Statistically significant results from under powered tests generally over estimate the truth (see my post on the Winner’s curse for why).
So when you detect an effect from peeking, you are very likely over estimating your impact. When you roll out the change globally, you’re probably not going to see the impact you expected. This can lead to disappointment (and a lot of questions from everyone when they don’t see changes to the numbers on a dashboard).
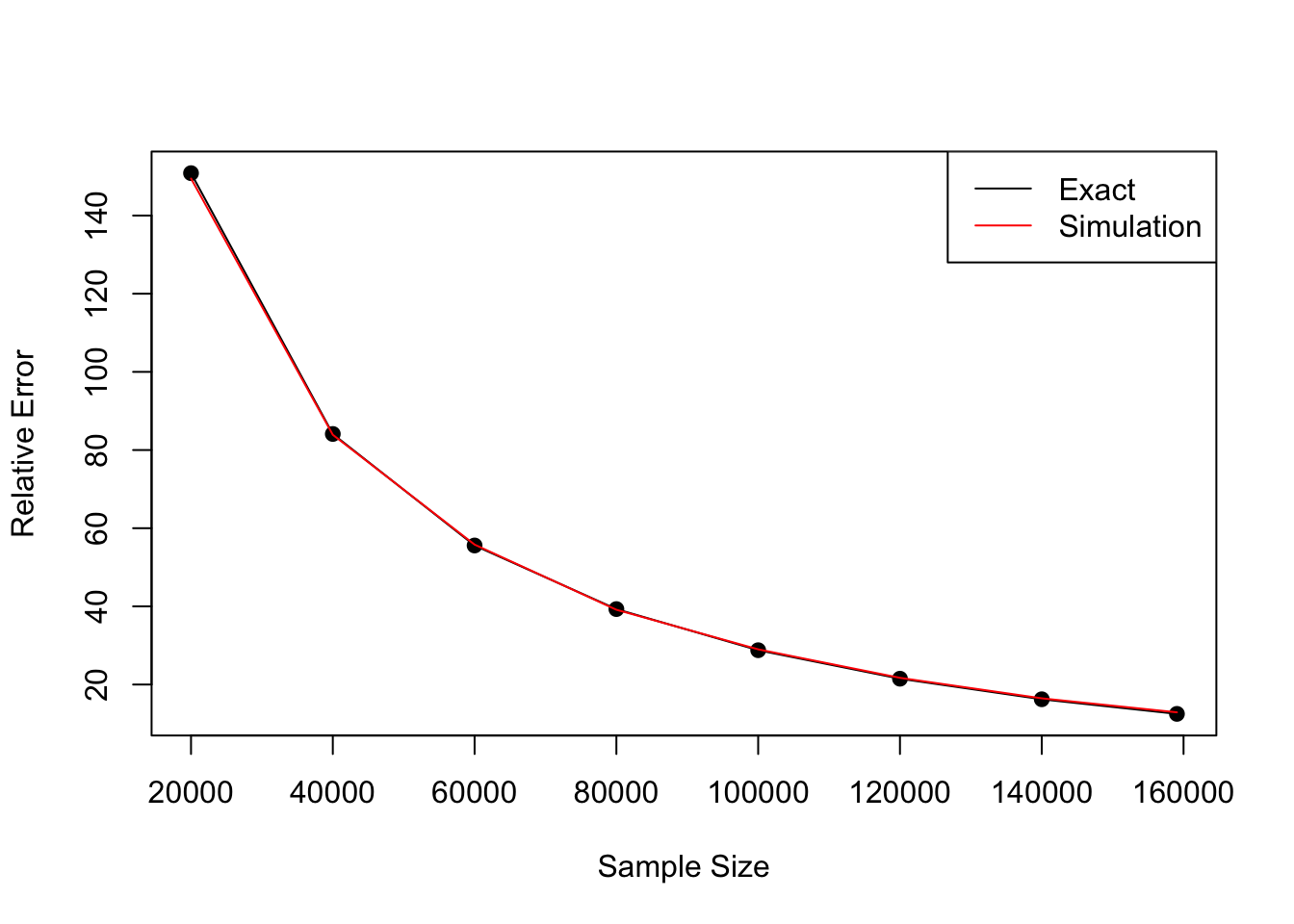
As a concrete example, say you design an experiment to detect a 3% lift in a binary outcome, and say your intervention truly does improve the outcome by 3%. The baseline is 10%, and you design your experiment to have 80% power with a 5% false positive rate. You’re going to need a total of 318,132 users in your experiment…which sounds like a lot. What if we instead checked for statistical significance each time the groups hit a multiple of 20, 000. Depending on how fast we can accrue users into the experiment, this could save time…right?
Shown below is a line plot of the relative error between what you would expect to detect at each peek and the true lift. The plot speaks for itself; conditional on finding an effect early, you’re likely over estimating the truth.
In the best case scenario, where you end the experiment on the first peek, you’re going to vastly over estimate the impact you had (almost by a factor of 2.3x!). The worst part is that these errors compound, so if you peek on every experiment you’re going to grossly over estimate the total impact you had. Maybe something to talk to your PMs about.