Pre Randomized Experiment Differences Don’t Mean DiD is Needed
Author
Demetri Pananos
Published
August 16, 2025
Take a look at this interaction I had with user jginestet on Cross Validated. In short, jginestet suggests that a randomized experiment assessing percent changes in tumor volume should adjust for pre-experiment differences (at this point, I’m nodding yes) and therefore the most appropriate method is DiD – difference in differences – (at this point, I’m shaking my head no).
User jginestet is right, pre-experiment differences should be adjusted for, but he is wrong when he suggests DiD is the way to do it. Let me explain
Point 1: Before Intervention, Treatment and Control are Samples From The Same Population
By virtue of this point, the two groups have the same pre-experiment mean outcome in expectation. The sample means are going to differ because of sampling variability. If \(\bar{Y}_i\) is the sample mean in group \(i \in \left\{t, c\right\}\), then mathematically this means that before intervention\(E[\bar{Y}_t] = E[\bar{Y}_c] = E[Y]\). The same can’t be said for post intervention, and that is why we run the experiment. What does this mean for DiD?
Let \(\bar{Y}_{i, j}\) indicate sample mean for group \(i \in \left\{ t, c \right\}\) in time period \(j \in \left\{ 0, 1 \right\}\) (here 0 means before intervention, 1 means after intervention). DiD estimates the following quantity
\[ \widehat{\Delta} = (\bar{Y}_{t, 1} - \bar{Y}_{t, 0}) - (\bar{Y}_{c, 1} - \bar{Y}_{c, 0}) \] If the treatment assignment is randomized, something nice happens now. Taking expectations
Which is the difference in means after the intervention. DiD is not needed in randomized experiments because the pre-treatment difference is 0 in expectation. We don’t need to adjust for pre-experiment systematic differences because there are none. Both treatment and control are samples from the same population. They therefore share population parameters. This is unlike most applications of DiD where groups do not share population parameters.
Point 2: If You Have Pre Experiment Data, You Should Condition On It!
That being said, there is value to adjusting for pre-experiment data, just not with DiD. Consider the following simulation:
I simulate a randomized experiment.
I have a highly correlated, pre-experiment outcome (e.g. could be weight in an intervention intended to help people lose weight). This is important since if the pre-experiment outcome was not correlated with post experiment outcome, the whole point of using, or even checking, pre-experiment outcomes would be moot.
I fit a model using treatment indication with and without the pre-experiment data.
I compare coverage of the confidence intervals, hoping that they would have nominal coverage.
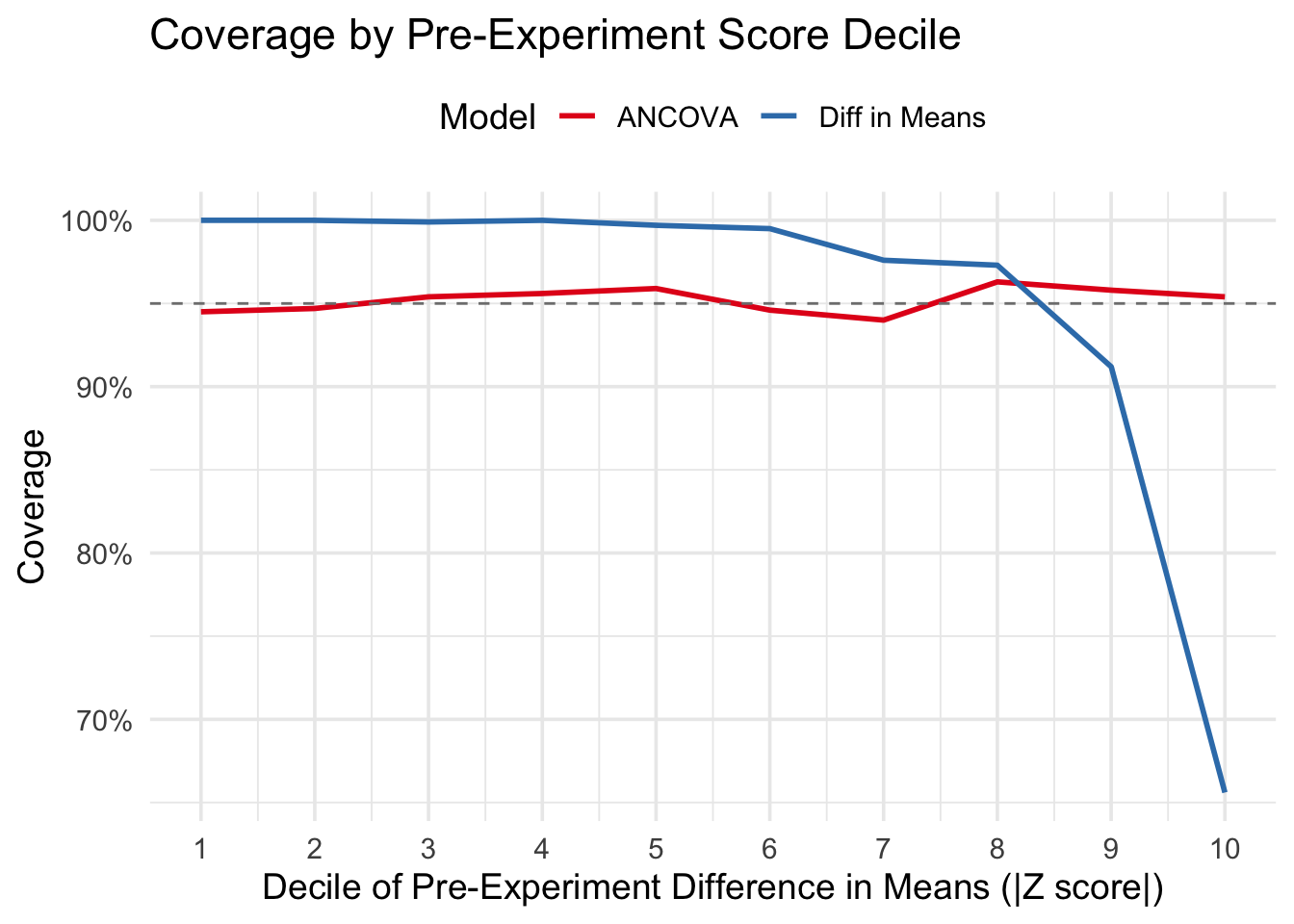
And, if you run this simulation, you find they do indeed have nominal coverage. But something interesting happens when you examine coverage as a function of the pre experiment differences. See the plot below.
This plot shows the coverage of the 95% confidence interval for the treatment effect within deciles of the standardized pre-experiment difference (essentially the absolute value of the z score for the difference). Note that for ANCOVA, the coverage is always at the nominal level, regardless of how big the pre-experiment differences are. But the difference in means has larger than expected coverage when pre-experiment differences are “small”, and wildly low coverage in cases where pre experiment differences are big. Despite this, each method maintains nominal coverage across all simulated experiments.
Why does this matter? This plot is telling me that, so long as the outcomes are highly correlated, then pre-experiment differences should be adjusted for … with ANCOVA. These points are nicely summarized at a higher level in the section titled “Balance of prognostic factors is necessary for valid inference” from Senn’s “Seven myths of randomization in clinical trials”.
So, should pre experiment imbalance be adjusted for? Well yes. We’ve seen that coverage in this case can be quite small when imbalance is big and pre experiment outcomes are highly correlated with post experiment outcomes. If you know the imbalance is big then presumably you have the data to demonstrate that, so you can adjust for it with ANCOVA.
Could you use DiD? Yes, you could, but there is no need to do so since the pre experiment population means are the same in expectation.
Those who insist on DiD in the randomized case are right – that we should adjust for pre experiment imbalance – for the wrong reasons – because I presume they think there is a systematic difference between groups; there isn’t.